Organisations invest heavily in robust systems, talented personnel, and sophisticated tools to ensure smooth operations. Yet small anomalies often escape attention — minor glitches in applications, occasional lags in processes, or subtle irregularities in performance metrics. These may appear insignificant in isolation. But when left unaddressed, they follow the principle of compounding effects, cascading into significant disruptions that lead to operational inefficiencies, financial losses, and reputational damage.
For Indian enterprises operating mission-critical systems — banks processing millions of UPI transactions daily, healthcare platforms managing patient data under stringent compliance requirements, government digital services serving hundreds of millions of citizens — the compounding cost of ignored anomalies is not theoretical. It is the root cause behind some of the most costly incidents in recent years.
The Domino Effect of Overlooked Anomalies
A small irregularity in one part of an enterprise system might initially appear inconsequential — a delayed API response, a misconfigured server setting, or a minor discrepancy in data synchronisation. However, these small issues often escalate as they propagate across interconnected systems, creating consequences far disproportionate to their apparent severity.
Subtle performance drops create compounding revenue impact. A 2% increase in page load time may not raise alarms initially — it does not breach any threshold, does not trigger any alert, and does not appear in any dashboard as a red indicator. However, if the delay is consistent, it creates a measurable drag on user experience. For e-commerce platforms, research consistently shows that every additional second of load time reduces conversion rates. Over weeks and months, what appeared to be an insignificant performance variation translates into millions in lost revenue, higher bounce rates, and reduced customer engagement — all without a single incident ticket ever being filed.
Data integrity errors corrupt decision-making silently. A small error in data migration or synchronisation may go unnoticed initially — a timestamp format inconsistency, a rounding error in financial calculations, or a missing field in a data pipeline. Over time, such errors corrupt analytics insights across the organisation. Business decisions are made on flawed data. Forecasts are inaccurate. Compliance reports contain discrepancies that surface only during audits, months after the original error occurred. For Indian financial institutions subject to RBI reporting requirements, these silent data integrity issues carry regulatory consequences that far exceed the effort that would have been required to catch them early.
Systemic overload builds from minor inefficiencies. A misconfigured database query causing minor lags might function perfectly under normal load. But under peak conditions — month-end batch processing, festival season traffic, salary day transaction volumes — that same minor inefficiency becomes the bottleneck that brings the entire system to its knees. The lag that was ‘not worth fixing’ becomes the outage that costs crores.
Why These Anomalies Go Undetected
The challenges are structural, not individual. They reflect fundamental limitations in how most enterprises approach operational monitoring.
Volume and complexity of data overwhelm human analysis. Enterprises generate massive amounts of data daily. Sifting through logs, metrics, events, and traces — collectively known as MELT data — to identify small but meaningful anomalies is genuinely difficult at scale. The sheer volume means that minor deviations are buried under layers of information. A subtle increase in garbage collection frequency on one of fifty application servers is invisible when you are looking at aggregate dashboards.
Lack of contextual correlation hides impact. Small anomalies in isolation often appear harmless. A minor network latency increase. A slight uptick in database connection times. A marginal increase in API error rates. Each, viewed independently, falls well within acceptable ranges. Without tools to correlate these anomalies across systems — to recognise that the network latency increase and the database connection time increase and the API error rate increase are all connected through a shared infrastructure component — teams cannot identify the pattern or understand the broader impact until it escalates into a visible outage.
Human oversight naturally prioritises the visible. Manual monitoring relies on human judgement, which is inherently biased toward visible, immediate problems. When a dashboard shows a red alert and a yellow warning simultaneously, the team addresses the red alert. The yellow warning — which might be the early signal of a far more serious problem — gets deferred. Over time, this deferral creates a backlog of unaddressed minor issues that compound into systemic fragility.
Resource constraints force trade-offs. Monitoring every minor irregularity with the same attention as major incidents requires resources that many enterprises cannot spare. Teams are understaffed relative to the complexity they manage. They prioritise high-impact, visible areas — production applications, customer-facing services, revenue-critical transactions — and less visible parts of the system receive less attention. It is in these less-monitored corners that small anomalies fester.
Inadequate tooling creates blind spots. Traditional monitoring tools often operate in silos, each covering a specific layer of the stack. The infrastructure monitoring tool sees server metrics but not application behaviour. The APM tool sees transaction traces but not network performance. Without cross-layer visibility and correlation, small issues that span multiple domains go undetected until they cascade.
The Cost of Neglect
Financial impact is direct and measurable. Unresolved small issues lead to downtime, productivity loss, and increased operational costs. Gartner estimates that the average cost of IT downtime is 5,600 per minute, with cumulative annual losses reaching into the millions for enterprises. For Indian enterprises — where digital transaction volumes are among the highest in the world — the per-minute cost of downtime in critical systems can be even higher when factoring in regulatory penalties and customer compensation.
Reputational damage compounds over time. End users have increasingly little tolerance for performance issues. Frequent lags, glitches, or system outages erode customer trust, leading to churn and negative reviews that damage brand reputation. In India’s digital marketplace — where switching costs are low and competition is intense — reputational damage from operational unreliability translates directly into customer attrition that is difficult and expensive to reverse.
Operational inefficiencies drain strategic capacity. Small anomalies, when compounded, create inefficiencies across departments. Recurring delays in data processing disrupt workflows, delay project timelines, and affect overall productivity. Engineering teams spend 30 to 40% of their time on incidents and troubleshooting — time that could be invested in building new capabilities, improving architecture, and driving the digital transformation that the business depends on.
Missed opportunities represent hidden losses. Flawed analytics or delayed insights caused by data anomalies result in missed business opportunities. Market trends are not capitalised on because the data was corrupted. Supply chain optimisations are not implemented because the analysis was based on inaccurate inputs. Product decisions are made on flawed customer behaviour data because a data pipeline error went undetected for weeks.
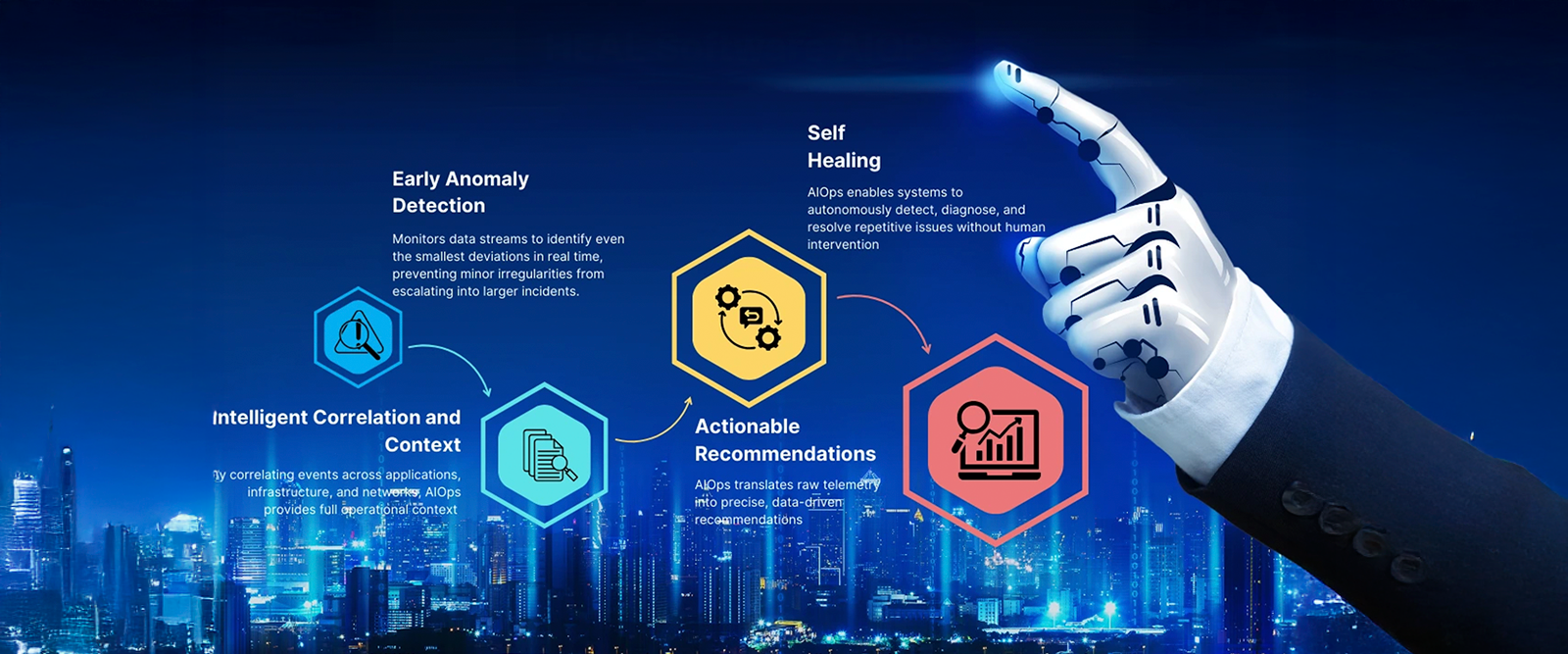
Proactive Anomaly Management: The iStreet Approach
Addressing small anomalies before they compound requires a fundamentally different operational approach — one that replaces manual, threshold-based monitoring with intelligent, continuous, context-aware detection and response.
Centralised observability integrates logs, metrics, events, and traces across systems into a unified view of system health. This eliminates the blind spots created by siloed monitoring tools and allows teams to detect anomalies in real time with full cross-layer context. When a minor network issue correlates with a minor database issue and a minor application issue, the centralised view reveals the connection that isolated tools miss.
Machine learning-driven anomaly detection goes beyond static thresholds to identify patterns that deviate from learned normal behaviour. These models detect subtle issues that escape human observation — gradual performance degradation, unusual usage patterns, slowly accumulating resource consumption — and flag them before they reach the tipping point of visible impact.
Predictive analytics leverages historical data to forecast potential issues before they occur. By recognising the precursor patterns that historically precede specific failure modes, the system enables preemptive action — scaling resources, optimising configurations, or alerting teams — before the failure materialises.
Automated remediation resolves common issues without human intervention. When the system detects a known pattern — an application exceeding CPU usage thresholds, a database connection pool trending toward exhaustion, a cache nearing capacity — it executes predefined corrective actions automatically, maintaining system stability without requiring an engineer to investigate, diagnose, and manually intervene.
Automated root cause analysis traces anomalies back to their origin, allowing teams to address the root cause rather than treating symptoms. This prevents recurrence and ensures long-term system health — breaking the cycle of recurring incidents that consumes engineering capacity quarter after quarter.
Real-World Impact: Resolving High Memory Utilisation for a Global Bank
A leading multinational bank — with 2,000 branches, 2,886 ATMs, and over 25 million users — faced a recurring issue of high memory utilisation in their core banking applications powered by Infosys Finacle. Despite handling 393 million transactions annually with support from IT operations teams and infrastructure vendors, the bank struggled to identify the root cause of this anomaly.
Initially, the memory issue appeared infrequent and did not impact daily operations. It was categorised as a low-priority item — the kind of minor anomaly that gets discussed in weekly reviews but never prioritised for investigation. However, as the issue became more frequent over months, it began posing risks of operational instability. What had started as an occasional spike became a pattern that was leading to 47+ hours of downtime per month and costing 11.5 million monthly in lost revenue, SLA penalties, and operational overhead.
HEAL Software’s AIOps solution — deployed as part of the bank’s operational resilience programme — used advanced anomaly detection and root cause analysis to identify the actual cause: misconfigurations in application parameter values that were causing the memory spikes. These misconfigurations had existed since a deployment months earlier but had been invisible to threshold-based monitoring because they only manifested under specific workload conditions.
With the platform’s recommendations, the bank optimised the parameter settings, reducing memory consumption and preventing future disruptions. The result: a 10% month-on-month reduction in outages and a return to operational stability — achieved by catching and fixing the kind of small anomaly that traditional monitoring would have continued to miss.
Small Anomalies, Strategic Risk
Small anomalies in enterprise systems are not trivial. Like a slow leak in a dam, they may initially seem negligible but can lead to catastrophic consequences if ignored. The AIOps market’s projected growth — from 6.5 billion in 2022 to 21.1 billion by 2027 — underscores the growing recognition that intelligent anomaly management is not a luxury but a necessity.
For Indian enterprises navigating rapid digital transformation alongside increasing regulatory scrutiny, proactive anomaly management is a governance imperative. Organisations without proactive frameworks incur 30% higher costs due to system failures compared to those with advanced monitoring solutions. The choice is clear: invest in prevention or pay for consequences.
iStreet Network’s AI-native approach — through our Resilient Operations portfolio powered by HEAL Software — ensures that the small things never become the big things. Because in a world where the smallest oversight can lead to the largest disruptions, vigilance and intelligence are the keys to thriving in complexity.
Talk to our advisors to explore how iStreet prevents small anomalies from becoming enterprise crises.
Originally inspired by insights from HEAL Software, an iStreet Network AIOps product. Learn more at healsoftware.ai.














