A Problem You Can Feel Before You Can Measure It
If you are a CIO or IT leader at an Indian enterprise, you do not need a report to confirm what your teams are telling you every week: things are getting harder to manage. The stack is deeper. The dependencies are denser. And every new cloud service, microservice, or integration your business adopts adds another thread to an already tangled web.
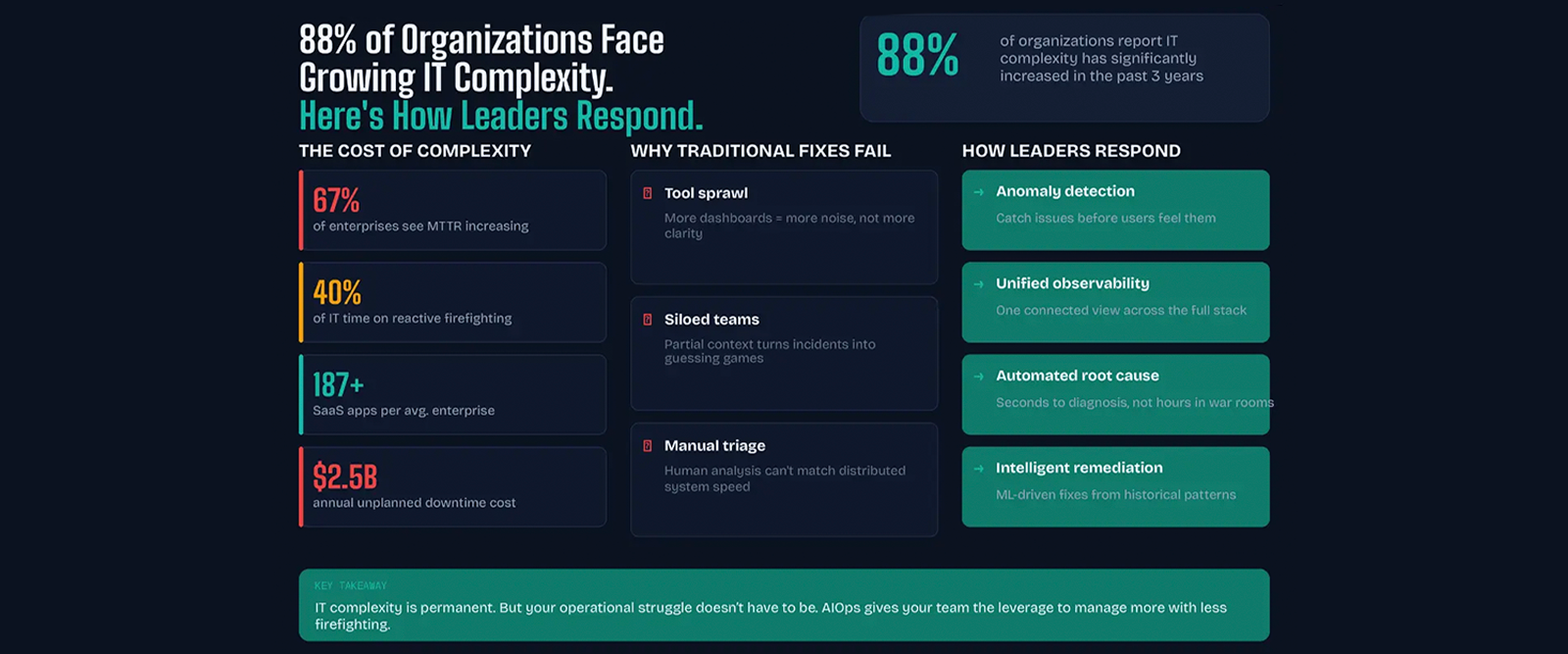
But the data makes the scale of the issue impossible to ignore. Industry research shows that 88% of organizations have reported a significant increase in IT complexity over the past three years. At the same time, mean time to resolution is climbing at two-thirds of enterprises, IT teams are spending up to 40% of their hours on low-value troubleshooting, and unplanned downtime is costing Fortune 1000 companies an estimated $1.5 billion to $2.5 billion per year. For Indian enterprises, particularly those in BFSI, healthcare, and government digital services, the numbers are proportionally devastating when measured against margin pressures, regulatory mandates, and the velocity of digital adoption.
These are not isolated pain points. They are symptoms of the same underlying condition: IT environments have outgrown the tools and processes designed to manage them. And that gap is widening with every new deployment, every new cloud region, every new compliance framework, and every new customer-facing digital product your organisation launches.
The Default Response Is Making It Worse
Faced with this growing strain, most organisations reach for the familiar playbook: add another monitoring tool, stand up another dashboard, hire another engineer. It is an understandable instinct, when you cannot see the problem clearly, the logical response is to add more eyes. But it is also the reason the average enterprise now juggles 10 to 40 overlapping management tools, each one covering a slice of the environment while none of them can see the whole picture.
The consequences of this tool sprawl ripple outward in ways that are deeply structural. Infrastructure, application, and network teams end up operating in parallel silos, each with their own data, their own dashboards, their own alerting rules, and their own escalation paths. When a cross-domain incident hits say, a database connection pool exhaustion that manifests as API timeouts, which then cascade into checkout failures and trigger health check alerts across multiple services diagnosing it becomes a coordination exercise across three or four teams, each armed with partial context. What should take minutes now takes hours. War rooms fill up. Slack channels explode. Senior engineers who should be building the future are instead playing detective, manually stitching together clues from a dozen different tools to reconstruct what happened.
Even the most experienced engineers hit a ceiling here. Human-scale analysis simply cannot correlate thousands of signals across distributed systems fast enough to keep up with the speed at which modern incidents propagate. The problem is not talent or effort it is that the operational model was designed for an era when everything ran in one data centre and a senior administrator could hold the entire topology in their head. Every application had a clear owner. Every dependency was documented. Every failure mode had been seen before.
That era is over. Hybrid cloud, microservices, containerised workloads, third-party API integrations, edge computing, and AI-driven workloads have created operational environments so complex that no human no matter how skilled can maintain a complete mental model of the system. And the CIOs who have recognised this are approaching the challenge from a fundamentally different direction.
What Leading CIOs Are Doing Differently
The shift is not about working harder within the old model. It is about replacing the model entirely. And the change comes down to one core idea: instead of adding more human effort to match growing complexity, use intelligent systems to absorb it.
In practice, this plays out across three dimensions.
First, leading organisations are moving from threshold-based alerting where you learn about a problem only after it has already started hurting users to AI-driven anomaly detection that flags deviations before they cascade into incidents. Traditional alerting is like an alarm that goes off when the building is already on fire. AI-driven anomaly detection is like a sensor that detects the wiring overheating, giving you time to intervene before damage occurs. The distinction is not incremental. It is categorical. It is the difference between reactive containment and proactive prevention.
Second, they are consolidating their fragmented toolsets into platforms that ingest data from across the full stack and correlate it automatically. Rather than asking a human to mentally stitch together signals from a dozen dashboards comparing timestamps, tracing service dependencies, cross-referencing deployment logs the platform builds the connected picture in real time. It shows not just what happened, but how one layer affected another, which services are downstream of the failure, and which business transactions are at risk. This connected, contextual view is what separates observability from operational intelligence.
Third, they are automating the diagnostic process itself. Instead of assembling a war room and spending hours tracing an issue through logs and runbooks, these organisations use machine learning to identify probable root causes in seconds and recommend the right remediation. For known failure patterns with established fixes, the system can execute remediation autonomously restarting a hung service, scaling a resource, or rolling back a faulty deployment without waiting for human intervention. The senior engineers who used to spend their days firefighting are now freed up to work on the architecture, automation, and strategy that actually move the business forward.
This approach is AIOps — Artificial Intelligence for IT Operations. And while the label has been around for a few years, what has changed recently is that the technology has matured enough to deliver on the promise. The machine learning models are more accurate. The integration ecosystems are more comprehensive. And the operational playbooks for deployment, tuning, and scaling are well established. AIOps is no longer an experiment. It is an operational strategy that leading enterprises are actively deploying.
AIOps, Demystified
If you have been in enterprise, IT long enough, you have earned a healthy scepticism of buzzwords. So let us be specific about what AIOps actually does when it is implemented well. It is an operational intelligence layer that sits across your entire environment — not replacing your existing monitoring tools but augmenting them with the analytical capabilities that individual tools lack.
At its foundation, an AIOps platform continuously ingests operational data, logs, metrics, traces, events, topology maps from every layer of the IT environment. But ingestion is just the starting point. The real value is what happens next.
Noise reduction. Machine learning clusters and deduplicates the thousands of alerts that fire during a single incident, surfacing one actionable event instead of five hundred redundant notifications. Instead of an on-call engineer wading through a flood of pages, they see a single, contextualised incident with ranked probable causes. This alone can reduce alert volume by 60 to 85% — a transformation in operational sanity.
Pattern recognition. The platform learns what ‘normal’ looks like for your specific environment accounting for time-of-day patterns, seasonal traffic variations, deployment schedules, and workload characteristics and identifies deviations early. It catches the slow memory leak on Tuesday that would have become Saturday’s outage. It flags the gradual increase in API latency that indicates an upstream service is degrading. It detects the disk I/O pattern that historically precedes database failures. This is not threshold-based alerting with a smarter threshold. It is behavioural analysis that understands context.
Contextual diagnosis. When something does go wrong, AIOps correlates events across infrastructure, application, and network layers to isolate the probable cause — what used to be a multi-team, multi-hour investigation compressed into a single, ranked finding. The platform traces the incident through the service dependency graph, identifying which upstream change or failure could propagate to create the observed symptom pattern. Engineers start with a hypothesis, not a blank page.
Automated remediation. Based on historical resolution data, the platform can recommend a specific fix or, where policies allow, execute it autonomously restarting a hung service, scaling a resource, clearing a cache, or rolling back a faulty deployment without waiting for human intervention. This is self-healing the operational holy grail that turns known, repetitive incidents into automated, invisible resolutions.
Together, these capabilities do not just speed up existing workflows. They change the economics of IT operations, allowing teams to manage a more complex environment with fewer fire drills and more strategic bandwidth. The return is not just operational it is organisational. When your best engineers spend their time on architecture instead of firefighting, the compound effect on innovation, reliability, and business velocity is transformative.
Five Questions for Your Next Leadership Meeting
Before evaluating any platform or vendor, it helps to have an honest baseline of where your organisation stands today. These five questions can frame that conversation at your next leadership review:
How many monitoring tools do we maintain, and can any single one show us a cross-stack view of a production incident?
If the answer is ‘many tools, no unified view,’ you are paying for visibility without operational intelligence.
Has our mean time to resolution improved over the past twelve months or are we quietly losing ground?
Many organisations discover that despite increased investment, MTTR has actually increased as complexity has grown. If resolution is getting slower, the problem is structural.
What percentage of our senior engineers’ time goes to unplanned work versus planned initiatives?
If your most experienced engineers are spending more than a third of their time on incident response, you are consuming strategic capacity for tactical firefighting.
When we experience a multi-system outage, how long does it take to identify the root cause and how many people does it require?
If root cause identification routinely takes hours and involves multiple teams, your diagnostic process does not scale with your architecture.
If the business doubles its cloud footprint next year, can our current operating model absorb that without a proportional increase in headcount?
If the answer is no, your operations model has a linear scaling problem that will become a business constraint.
If the honest answers reveal gaps, that is not a failure, it is a signal. Nearly every enterprise we talk to at iStreet Network is somewhere on this spectrum. The ones pulling ahead are simply the ones who have decided to stop managing the gap with heroics and start closing it with a different kind of tooling.
The Complexity Is Permanent. The Struggle Does Not Have to Be.
Hybrid and multi-cloud architectures are not going to simplify themselves. AI workloads, edge computing, and evolving compliance requirements will only add new layers. The 88% figure from the headline is not a temporary spike it is the new baseline. Indian enterprises, in particular, face the compounding challenge of rapid digital adoption, world-leading transaction volumes, and an increasingly sophisticated regulatory environment. Complexity is the permanent condition of modern enterprise IT.
But that does not mean your operations have to feel as complex as your environment. The CIOs who are navigating this well have not found a way to eliminate complexity. They have built an operational layer intelligent enough to manage it, one that turns raw volume into signal, replaces guesswork with data-driven diagnosis, scales without requiring you to scale your team at the same rate, and continuously improves as it learns from every incident.
AIOps is how they are doing it. And the window to treat it as a competitive advantage — rather than a catch-up exercise is still open.
iStreet Network’s Resilient Operations solutions, powered by HEAL Software’s proven AIOps engine, deliver this intelligent operational layer for India’s most complex and regulated enterprises. From AIOps and GenAIOps to Full-Stack Observability to the Resiliency Operations Centre, we help enterprises turn operational complexity into operational clarity without adding to the stack.
Talk to our advisors to explore what this looks like in your environment.
Originally inspired by insights from HEAL Software, an iStreet Network AIOps product. Learn more at healsoftware.ai.














