According to a McKinsey report, 70% of digital banking transformations exceed budget and timelines — largely due to one core problem: underestimating system complexity. Financial institutions are not failing because of inadequate technology investment. They are failing because they cannot see how deeply intertwined their applications, services, and infrastructure really are.
Recent studies paint a stark picture. 45% of financial institutions face at least one major IT breakdown every quarter. The average Mean Time to Resolve for critical incidents sits at 4.2 hours. Each minute of downtime in banking systems costs approximately 9,000. These numbers are sobering on their own, but they become alarming when you consider the cascading consequences: regulatory penalties, customer attrition, reputational damage, and the compounding effect of repeated incidents on organisational trust.
Despite spending significantly on observability tools, many Indian banks and financial institutions still operate reactively. They chase alerts. They drown in dashboards. They make guesses. And when systems go down, they scramble across siloed teams trying to trace the issue manually — each team looking at their own slice of the infrastructure while the full picture remains invisible.
The root of the problem is not insufficient data or inadequate tooling. It is a basic lack of real-time contextual understanding across the technology stack. And that lack of understanding has a name: absent or inaccurate service dependency mapping.
A Fresh Approach: Service Dependency Mapping
Service Dependency Mapping — SDM — gives a real-time, detailed view of how every service in a digital system interconnects. It is not another dashboard. It is the connective tissue of modern AIOps. It does not just tell you something is wrong — it tells you what else the failure is affecting, who is downstream, and how to isolate the issue before it cascades into a full-scale outage.
SDM maps the entire service ecosystem: applications and microservices, the connection points between them through APIs, the databases they rely on, the infrastructure components that host them, and the network connections that tie them all together. But just having a static architecture diagram is not the goal. The aim is to uncover hidden dependencies — those quiet but critical relationships that often go unnoticed until something breaks.
Consider a practical example that occurs regularly in Indian banking operations. A payment authentication failure appears to be a front-end glitch — the user sees an error page, the support ticket describes a checkout failure. But the real issue is a delay in a shared database that also supports the KYC module. The payment service and the KYC service share a database dependency that was never explicitly documented because they were built by different teams at different times. Without SDM, figuring this out would take hours of guesswork — engineers on the payment team investigating their service, finding nothing wrong, escalating to the infrastructure team, who find nothing wrong with the server, while the actual root cause sits in a database connection pool that serves multiple services. With SDM, the cause and effect are instantly traceable because the dependency relationship is known, mapped, and continuously updated.
From Data Chaos to Operational Clarity
A service is a logical grouping of instances that perform a specific function or provide a specific capability. Every part of a digital service — be it a microservice authenticating users, a backend process computing loan eligibility, or an API facilitating external account verification — is a node in a contextual web. Understanding this web is the foundation of intelligent operations.
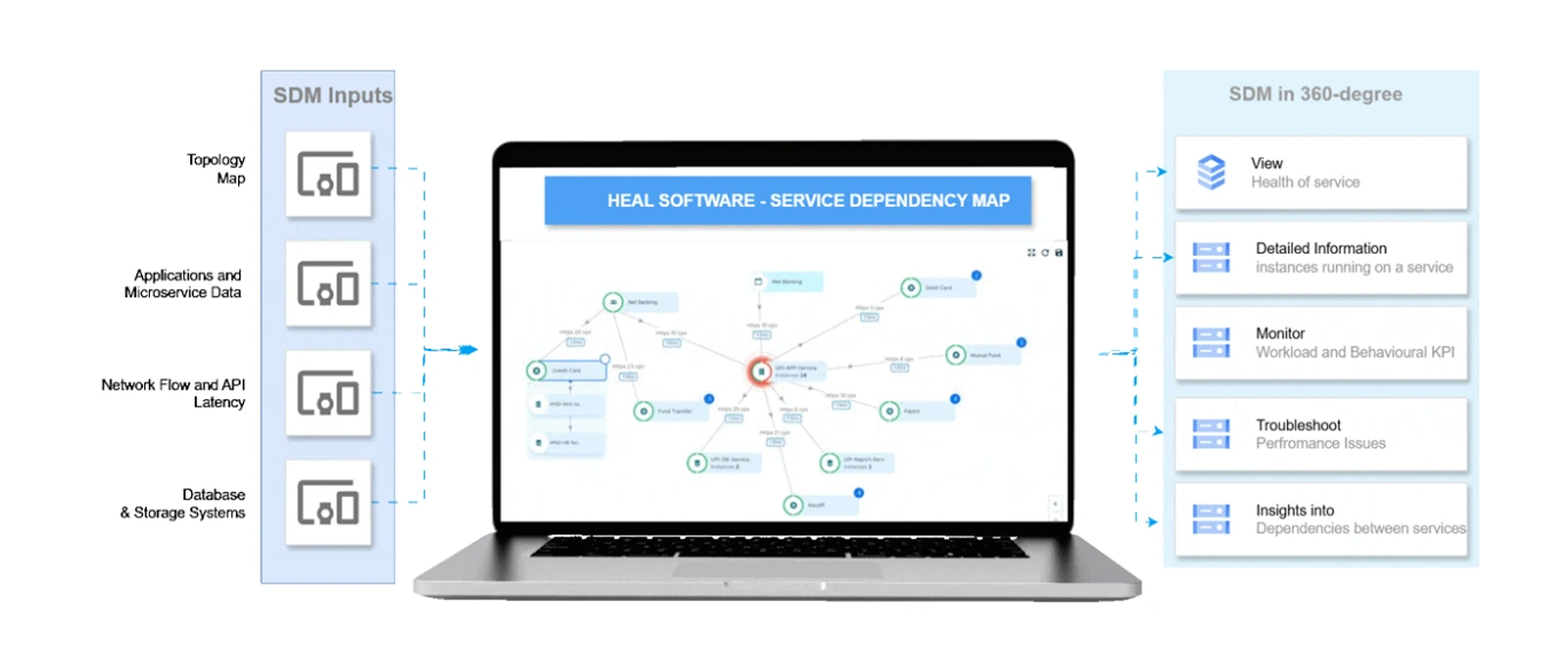
To truly operationalise SDM, the right inputs must come together. Topology maps provide the structural foundation — what connects to what. Application and microservice data provide the functional context — what each component does and how it behaves. Network flow and API latency data provide the performance context — how communication between components is actually performing in real time. And database and storage system telemetry provides the data layer context — how the persistent storage that underpins every transaction is performing.
These inputs, when ingested and modelled correctly, reveal a 360-degree view of service behaviour and relationship health. This is where SDM starts to pull ahead of traditional monitoring — not just telling you what is failing, but why it is failing, who it is affecting, and what else is at risk.
iStreet Network’s Resilient Operations solutions, powered by HEAL Software, go beyond static mapping. The platform continuously learns from actual traffic patterns — refreshing the dependency graph as architectures evolve, new services are deployed, and communication patterns change. This machine-learned topology, updated in near real-time from actual production traffic, provides a far more accurate foundation for correlation and diagnosis than manually maintained dependency maps that drift out of sync with reality as soon as the next deployment occurs.
The service dashboard translates this complex architectural intelligence into an operator-friendly, decision-ready view — with real-time visibility into service health, granular performance KPIs, and live dependency insights. It is where the unseen backbone of AIOps becomes operational intelligence at the fingertips of every engineer and operations leader.
Diagnosing Faster, Fixing Smarter
One of the most transformative benefits of SDM is its impact on Root Cause Analysis. Without dependency context, RCA is a manual investigation — engineers trace logs, correlate timestamps, check deployment histories, and test hypotheses sequentially. Each hypothesis takes time to investigate and validate. When the root cause crosses service boundaries or involves shared infrastructure, the investigation can take hours and require coordination across multiple teams.
With SDM, RCA becomes real-time. Engineers can trace issues back to the precise origin, whether it is a misconfigured load balancer, a database lock, a failed update in a shared library, or a configuration drift in a component that multiple services depend on. This surgical visibility minimises the ‘mean time to innocence’ — the time teams spend proving that their service is not the problem — and accelerates resolution by directing attention immediately to the actual root cause.
In industries like banking, where every second of downtime translates into lost transactions and compliance risk, the operational impact is measurable and significant: 50 to 70% reduction in MTTR for high-priority incidents, quicker resolution of escalations through intelligent routing that sends alerts to the team that actually owns the problematic service, and 30 to 40% improvement in SLA compliance because issues are resolved before they breach service level thresholds.
These are not just operational improvements — they are strategic differentiators that separate resilient institutions from those that are perpetually firefighting.
SDM: The Key to AI-Native Operations
For AI-driven operations to work, the intelligence layer needs to understand not just the event, but the ecosystem the event lives in. An alert about high CPU on a server is meaningless without knowing what services run on that server, what other services depend on those services, and what business transactions flow through that dependency chain.
SDM feeds AIOps the structured relationships it needs to perform causal inference (tracing from symptom to cause through the dependency graph), suppress alert noise intelligently (grouping related alerts based on known dependencies rather than just time proximity), enable smart escalation (routing incidents to the team that owns the root cause service, not just the team that owns the alerting threshold), and prevent incidents proactively (recognising when changes in one part of the dependency graph will create risk for downstream services).
This is why iStreet Network positions SDM not as a feature or a nice-to-have, but as foundational infrastructure — the unseen backbone that makes every other Resilient Operations capability effective. From AIOps and GenAIOps to Full-Stack Observability to the Resiliency Operations Centre, every solution in iStreet’s portfolio is more powerful, more accurate, and more valuable when built on accurate, continuously learning service dependency intelligence.
Service Dependency Mapping is not just a technical upgrade. It is a business imperative. For banks, financial institutions, healthcare providers, and government digital services across India, SDM is the future-ready foundation of resilient, intelligent operations. It transforms chaos to control, from reactive to predictive, and from firefighting to forecasting.
And in the evolving world of AIOps, that is not just competitive advantage. It is survival.
Talk to our advisors to explore how service dependency mapping can transform your enterprise operations.
Originally inspired by insights from HEAL Software, an iStreet Network AIOps product. Learn more at healsoftware.ai.














