According to industry benchmarks, unplanned downtime costs enterprises an average of 5,600 per minute. For industries like fintech, e-commerce, and SaaS — where customer experience is a competitive differentiator — prolonged outages translate into customer churn, SLA penalties, and reputational damage that compounds long after the systems are restored.
Mean Time to Resolution is no longer just an operational metric. It is a business-critical benchmark that defines an organisation’s resilience in the marketplace. Every second lost to prolonged system downtime translates into revenue loss and increased operational overhead. In the dynamic IT ecosystems of Indian enterprises — where distributed architectures, microservices, and hybrid cloud environments introduce multivariate complexity — delays in resolution are not just technical inefficiencies. They are direct financial liabilities.
The Complexity of Legacy Resolution
The flaw in legacy resolution approaches lies in their isolated, univariate diagnostics. Traditional monitoring tools detect anomalies independently — CPU spikes, database latency, and API slowdowns each trigger separate alerts without contextual intelligence to link them to a single root cause.
This creates a cascading set of operational failures. Alert overload consumes the first critical minutes — IT teams manually sift through fragmented signals, struggling to separate noise from critical issues. Root cause analysis becomes slow and unreliable — engineers rely on trial-and-error troubleshooting rather than automated correlation, investigating multiple hypotheses sequentially when the actual cause is a single upstream event. Remediation becomes inefficient and iterative — fixes are applied one at a time, verified, found ineffective, and replaced with new attempts, prolonging incident resolution while customer impact escalates.
This reactive model inflates MTTR systematically. Teams navigate false positives and redundant alerts before reaching a diagnosis — by which time the business impact has already escalated from minor degradation to full-scale disruption. For Indian banks processing millions of UPI transactions daily, or e-commerce platforms managing festive season traffic spikes, this delay is measured not in engineering hours but in crores of lost revenue and eroded customer trust.
AI and the Shift from Reactive to Predictive Resolution
To break this cycle, resolution must evolve from a reactive process to a predictive, automated function. iStreet Network’s Resilient Operations solutions, powered by HEAL Software’s AIOps engine, redefine incident management by employing multivariate correlation, real-time anomaly detection, and autonomous remediation.
AI applies statistical and machine learning models to recognise nonlinear relationships between disparate system events. Instead of analysing CPU, memory, network, and application logs as isolated datasets, AI interprets them as interconnected variables within a single probabilistic model — identifying causal patterns rather than just correlations. This is a fundamental analytical shift: from asking ‘which metric crossed a threshold?’ to asking ‘what combination of changes across the system best explains the observed failure?’
How AI-Driven Resolution Works: The Four-Stage Framework
Stage 1: High-Velocity Telemetry Ingestion
AI-powered incident resolution begins with comprehensive data ingestion. Modern IT environments generate vast amounts of telemetry data across multiple dimensions: application logs capturing API failures, transaction timeouts, and error codes; infrastructure metrics tracking CPU, memory, disk I/O, and network latency; network traces monitoring packet loss, routing anomalies, and bandwidth congestion; user behaviour analytics tracking session durations, drop-off points, and conversion trends; and security signals capturing authentication failures and anomalous access patterns.
Each of these data points exists in isolation within individual observability tools. The AIOps platform treats them as interconnected signals, continuously ingesting data from multiple sources in real time. The system handles high-velocity, high-volume streaming data, ensuring that even millisecond-level system fluctuations are captured and analysed. In a microservices architecture, it does not just ingest logs from individual services — it tracks dependencies between them, mapping how an error in one service impacts the entire chain of execution.
Stage 2: Unsupervised Learning for Anomaly Detection
Once telemetry data is ingested, the platform applies unsupervised learning models to establish dynamic baselines of normal system behaviour. Unlike traditional static thresholds — where CPU exceeding 80% triggers an alert regardless of context — AI dynamically adjusts baselines based on historical trends (comparing current performance with past patterns), seasonality awareness (recognising that traffic spikes at predictable times are expected, preventing false alerts), and workload fluctuations (understanding the impact of deployments, database migrations, or infrastructure scaling).
By continuously updating these baselines, the AI detects subtle deviations before they escalate — catching the gradual memory leak, the slowly increasing query latency, the creeping disk utilisation that would eventually cause an outage but sits below every static threshold.
Stage 3: Causal Relationship Mapping
Detecting anomalies is the first step — understanding their root cause is what truly accelerates resolution. AI-driven systems go beyond flagging irregularities by establishing causal relationships between events, enabling IT teams to focus on resolving the actual issue rather than getting lost in alert fatigue.
Graph-based correlation constructs a dependency map across the entire IT infrastructure, linking anomalies across different layers — applications, databases, networks, and cloud resources. If an application slowdown is due to a database bottleneck, AI groups related alerts into a single incident, reducing noise and streamlining resolution. Causal inference determines whether an anomaly is the root cause or a downstream effect. If network congestion is leading to API timeouts, AI prioritises fixing the network issue instead of flooding engineers with dozens of API failure alerts.
Stage 4: Autonomous Remediation
Once AI identifies the root cause, it initiates automated remediation workflows — transforming resolution from a reactive task into a proactive, self-healing process. This happens in three phases.
Automated decision-making assesses severity and impact, determines whether an automated fix can be executed without human intervention, and provides engineers with recommended action steps when manual approval is needed.
Self-healing workflows execute specific remediation actions: restarting crashed services with higher resource limits, auto-scaling database instances during high traffic, redirecting requests to redundant infrastructure to prevent bottlenecks, and rolling back unstable deployments to the previous stable version.
Predictive remediation goes beyond reaction to forecast failures before they occur. If the platform detects a gradual increase in latency, error rates, or resource exhaustion, it triggers preventive actions — database optimisation, cache refreshes, load balancer adjustments — before users are ever affected. In an enterprise environment, the AI might observe that memory consumption in a critical database cluster is increasing over successive deployments. Instead of engineers manually diagnosing the issue after performance degrades, AI proactively detects the trend, alerts teams, and recommends memory reallocation before an outage occurs.
This preemptive approach eliminates the delays associated with human intervention, reducing MTTR significantly compared to traditional reactive troubleshooting.
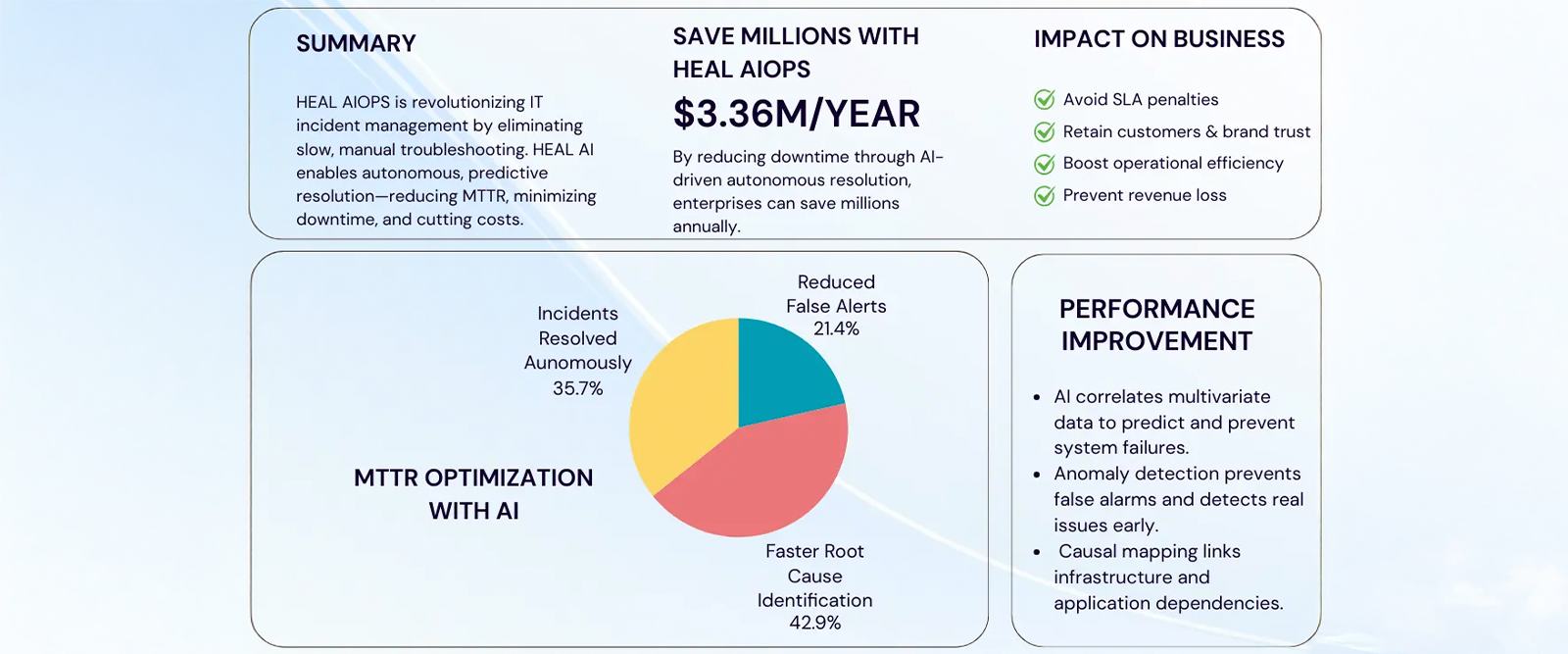
Beyond Faster Resolution: The Business Case
Reducing MTTR is not just an operational efficiency goal — it has direct financial implications. Organisations that have implemented AI-driven resolution strategies through iStreet Network’s solutions have reported 87% reduction in false alerts, allowing engineers to focus on critical incidents that actually require human attention. Root cause identification accelerates by four times or more, eliminating hours of manual investigation. Autonomous remediation handles 60% of incidents without human intervention — maintaining consistent quality that does not vary by which engineer is on-call or how fatigued the team is.
For Indian enterprises facing regulatory mandates around uptime, SLA compliance, and audit-ready operations — from RBI operational resilience guidelines to DPDP requirements — faster, more consistent resolution is not optional. It is the defining factor of operational excellence and regulatory compliance.
The Future of MTTR: AI as Core Infrastructure
As IT environments continue to scale in complexity, manual incident resolution will become unsustainable. AI is not merely an enhancement to observability; it is the foundation for next-generation IT operations, where systems are not just monitored but intelligently optimised in real time.
The organisations that lead in operational resilience will be those that move beyond reactive troubleshooting and embrace AI-driven resolution as a core strategy. In this new paradigm, MTTR is no longer a static metric — it is a continuously improving function, dynamically adapting to system behaviour, workload patterns, and evolving infrastructure needs.
Faster resolution is no longer optional. It is the defining factor of IT excellence. And iStreet Network’s Resilient Operations portfolio makes this operational for India’s most demanding enterprises.
Talk to our advisors to explore how AI-powered resolution can transform your enterprise MTTR.
Originally inspired by insights from HEAL Software, an iStreet Network AIOps product. Learn more at healsoftware.ai.














